MySQL性能调优(2)存储引擎介绍、体系结构及运行机理
目录
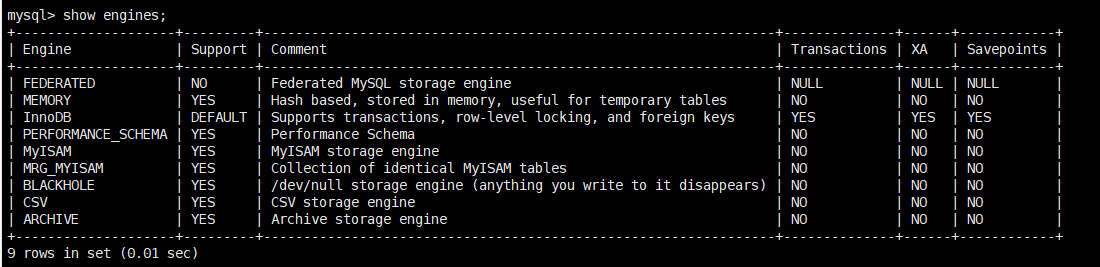
存储引擎介绍
- 插拔式的插件方式(存储引擎本身是数据库服务器的组件,负责对在物理服务器层面上维护的基本数据进行实际操作)
- 存储引擎是指定在表之上的,即一个库中的每一个表都可以指定专用的存储引擎
- 最新的MySQL 8.0 发布之后,对数据库数据字典方面做了较大的改进。
首先是,将所有原先存放于数据字典文件中的信息,全部存放到数据库系统表中,即将之前版本的.frm,.opt,.par,.TRN,.TRG,.isl文件都移除了,不再通过文件的方式存储数据字典信息。 其次是对INFORMATION_SCHEM,MySQL,sys系统库中的存储引擎做了改进,原先使用MyISAM存储引擎的数据字典表都改为使用InnoDB存储引擎存放。 从不支持事务的MyISAM存储引擎转变到支持事务的InnoDB存储引擎,为原子DDL的实现,提供了可能性。
| |
存储引擎
CVS存储引擎

- 数据存储以CSV文件
- 特点:
- 不能定义没有索引、列定义必须为NOT NULL、不能设置自增列 –>不适用大表或者数据的在线处理
- CSV数据的存储用,隔开,可直接编辑CSV文件进行数据的编排 –>数据安全性低 注:编辑之后,要生效使用flush table 表名 命令
- 应用场景:
数据的快速导出导入 表格直接转换成CSV
Archive存储引擎
- 压缩协议进行数据的存储
- 数据存储为ARZ文件格式
- 特点:
- 只支持insert和select两种操作
- 只允许自增ID列建立索引
- 行级锁
- 不支持事务
- 数据占用磁盘少
- 应用场景:
日志系统 大量的设备数据采集
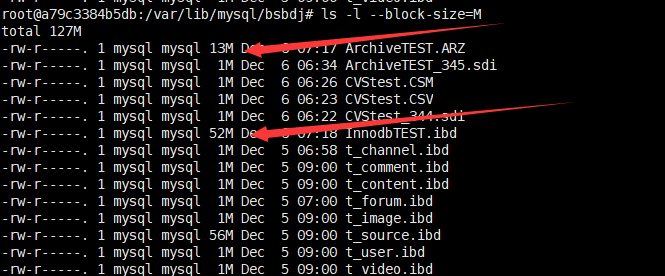
- 我同时在Archive和innodb同结构表中插入1000000条数据:看看大小区别:这是只有一个id和name的情况下。如果字段更多的话,archive的压缩率区别就更大了。
Memory存储引擎
- 数据都是存储在内存中,IO效率要比其他引擎高很多
- 服务重启数据丢失,内存数据表默认只有16M
- 特点:
- 支持hash索引,B tree索引,默认hash(查找复杂度0(1))
- 字段长度都是固定长度varchar(32)=char(32)
- 不支持大数据存储类型字段如 blog,text
- 表级锁
- 应用场景:
等值查找热度较高数据 查询结果内存中的计算,大多数都是采用这种存储引擎作为临时表存储需计算的数据 不过现在基本上用缓存数据库了
Myisam存储引擎
- MySQL5.5版本之前的默认存储引擎
- 特点:
- select count(*) from table 无需进行数据的扫描
- 数据(MYD)和索引(MYI)分开存储
- 表级锁
- 不支持事务
Innodb存储引擎
- 现在是数据库默认引擎
- 特点:
- 支持事务
- 行级锁
- 聚集索引(主键索引)存储,如果没有主键,那么会有唯一键来做索引,如果还没有就生成一个隐藏的主键索引。
- 支持外键关系保证数据完整性(不过我现在开发中比较少用了。依开发项目实质性来取决于做不做外键关联。)
| |
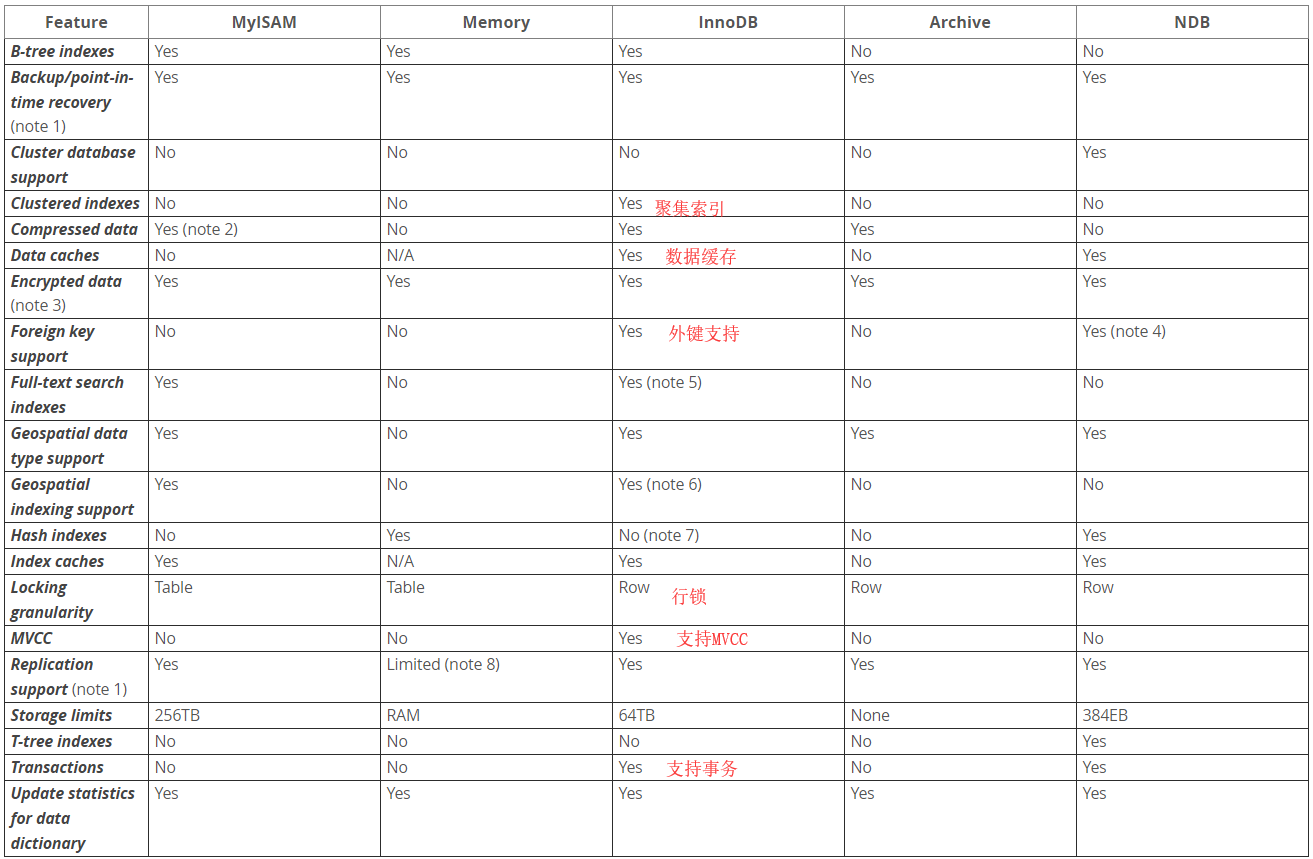
对比
MVCC是多版本并发控制:后续单独分析;
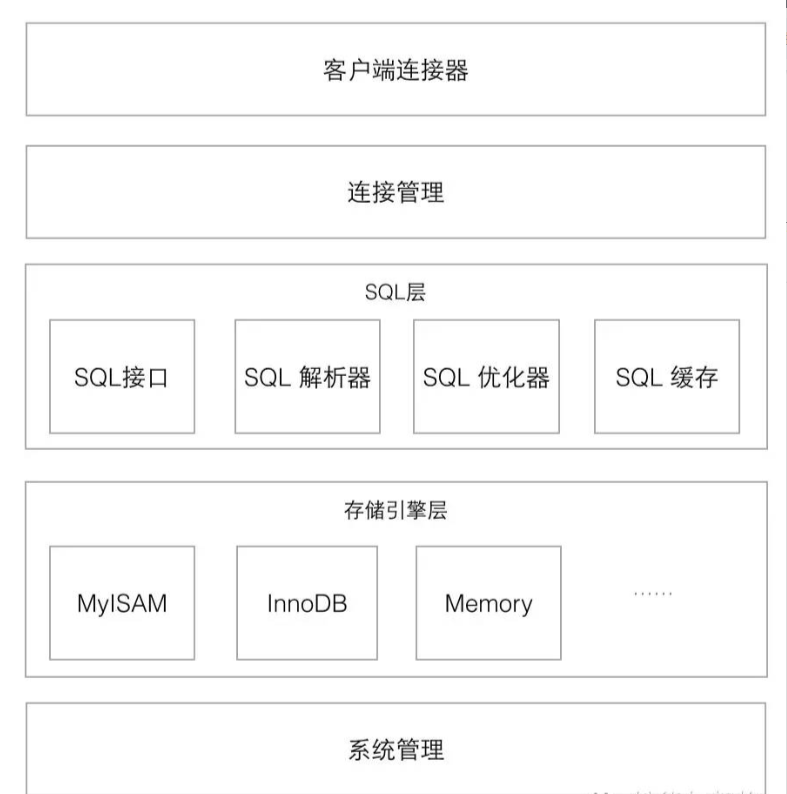
MySQL体系结构及运行机理
- 先看看体系结构
| |