MySQL性能调优(3)查询优化详解
查询执行路径
 ##### MySQL 客户端/服务端通信
- MySQL客户端与服务端的通信方式是“半双工”;
- 客户端一旦开始发送消息,另一端要接收完整个消息才能响应。客户端一旦开始接收数据没法停下来发送指令。
- 对于一个MySQL连接,或者说一个线程,时刻都有一个状态来标识这个连接正在做什么
- 查看命令 show full processlist / show processlist
我正在通过navicat向虚拟机里面的数据库导入数据
##### MySQL 客户端/服务端通信
- MySQL客户端与服务端的通信方式是“半双工”;
- 客户端一旦开始发送消息,另一端要接收完整个消息才能响应。客户端一旦开始接收数据没法停下来发送指令。
- 对于一个MySQL连接,或者说一个线程,时刻都有一个状态来标识这个连接正在做什么
- 查看命令 show full processlist / show processlist
我正在通过navicat向虚拟机里面的数据库导入数据
 ```
Sleep 线程正在等待客户端发送数据
Query 连接线程正在执行查询
Locked 线程正在等待表锁的释放
Sorting result 线程正在对结果进行排序
Sending data 向请求端返回数据
可通过kill {id}的方式进行连接的杀掉
```
[官网状态全集](https://dev.mysql.com/doc/refman/8.0/en/general-thread-states.html)
```
Sleep 线程正在等待客户端发送数据
Query 连接线程正在执行查询
Locked 线程正在等待表锁的释放
Sorting result 线程正在对结果进行排序
Sending data 向请求端返回数据
可通过kill {id}的方式进行连接的杀掉
```
[官网状态全集](https://dev.mysql.com/doc/refman/8.0/en/general-thread-states.html)查询缓存
- 前话:为什么MySQL默认关闭了缓存开启??
MySQL 8.0不支持查询缓存,用户升级后将被鼓励使用服务器端查询重写或ProxySQL作为中间缓存。
下面是了解缓存应该知道的知识:
- 工作原理:
缓存SELECT操作的结果集和SQL语句; 新的SELECT语句,先去查询缓存,判断是否存在可用的记录集;
- 判断标准:
与缓存的SQL语句,是否完全一样(包括语句内的空格),区分大小写 (简单认为存储了一个key-value结构,key为sql,value为sql查询结果集)
- 不会缓存的情况
- 当查询语句中有一些不确定的数据时,则不会被缓存。如包含函数NOW(),CURRENT_DATE()等类似的函数,或者用户自定义的函数,存储函数,用户变量等都不会被缓存
- 当查询的结果大于query_cache_limit(查询缓存返回行数)设置的值时,结果不会被缓存
- 对于InnoDB引擎来说,当一个语句在事务中修改了某个表,那么在这个事务提交之前,所有与这个表相关的查询都无法被缓存。因此长时间执行事务,会大大降低缓存命中率
- 查询的表是系统表
- 查询语句不涉及到表
- 当前表在之前做过其他增删改,这个表中其他数据做的缓存都会失效、
比如当前表中一行数据你做了缓存,表中其他数据更改了,也会影响这行数据的缓存失效。
查询优化处理
- 解析sql
通过lex词法分析,yacc语法分析将sql语句解析成解析树学习连接
- 预处理阶段
根据MySQL的语法的规则进一步检查解析树的合法性,如:检查数据的表和列是否存在,解析名字和别名的设置。还会进行权限的验证
- 查询优化器
优化器的主要作用就是找到最优的执行计划
如何找到最优执行计划
- 使用等价变化规则
5 = 5 and a > 5 改写成 a > 5 a < b and a = 5 改写成 b > 5 and a = 5 基于联合索引,调整条件位置等
- 优化count 、min、max等函数
min函数只需找索引最左边(因为innodb本身索引有序) max函数只需找索引最右边(因为innodb本身索引有序)
myisam引擎count(*)
- 覆盖索引扫描
比如你查询返回的字段命中了索引,他就会直接返回数据:这里我给uname建立了索引

- 子查询优化(我们做优化的话:最好就是把子查询改成连接查询)
子查询合并。即把多个子查询合并成一个子查询,作用是减少元组扫描的次数 子查询反嵌套。也称作子查询上拉,即将子查询重写为等价的多表连接 聚集子查询消除。即聚集函数上推,将消除聚集函数的子查询与父查询做外连接
- 提前终止查询 用了limit关键字(他就索引limit长度的数据)或者使用不存在的条件;
- IN的优化
先进性排序,再采用二分查找的方式; 在条件多的情况下,or还是会一个个去扫描判断,而in他会先找到中间的在判断;再根据大小判断。这样就会减少多余的扫描。
MySQL的查询优化器是基于成本计算的原则。他会尝试各种执行计划。数据抽样的方式进行试验(随机的读取一个4K的数据块进行分析)
查询执行引擎
执行计划顺序
select查询的序列号,标识执行的顺序
| |
查询类型select_type
| |
执行计划table
查询涉及到的表,直接显示表名或者表的别名
| |
执行计划type
所以优化得至少在range及以上
| |
其他关键字
| |
额外信息Extra
- Using filesort :
MySQL对数据使用一个外部的文件内容进行了排序,而不是按照表内的索引进行排序读取
- Using temporary:
使用临时表保存中间结果,也就是说MySQL在对查询结果排序时使用了临时表,常见于order by 或 group by但是innodb用id排序分组是不会出现临时表的。
- Using index:
表示相应的select操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高
- Using where :
使用了where过滤条件
- select tables optimized away:
基于索引优化MIN/MAX操作或者MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段在进行计算,查询执行计划生成的阶段即可完成优化
分析一个组合查询
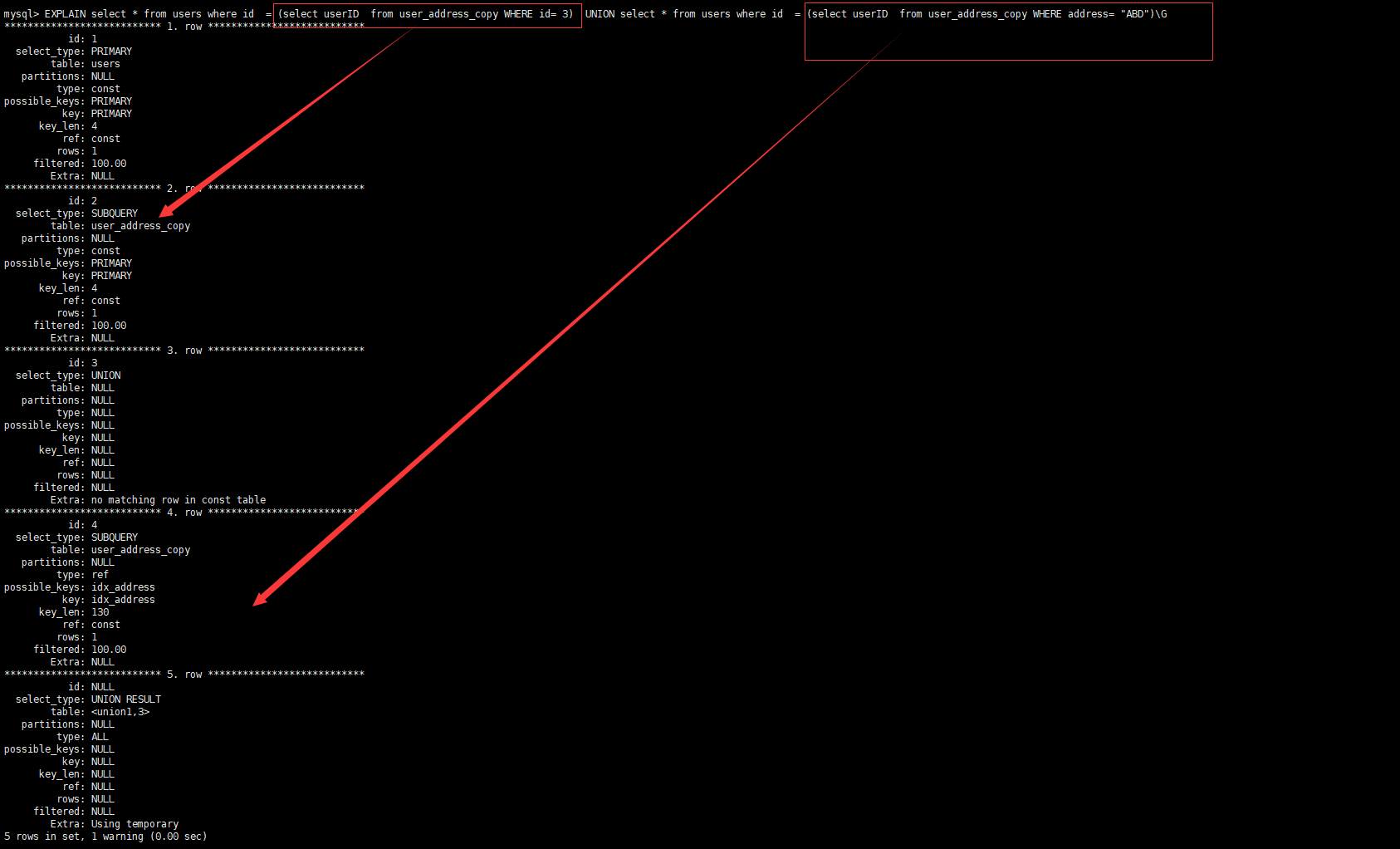
| |
执行引擎
调用插件式的存储引擎的原子API的功能进行执行计划的执行
返回客户端
增量的返回结果:
开始生成第一条结果时,MySQL就开始往请求方逐步返回数据 好处: MySQL服务器无须保存过多的数据,浪费内存用户体验好,马上就拿到了数据
慢查询日志
| |
慢日志文件查看

| |
MySQL自带的分析工具
| |
