MySQL性能调优(4)Innodb存储引擎的事务
事务
数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作;事务是一组不可再分割的操作集合(工作逻辑单元);
MySQL中如何开启事务:
| |
JDBC编程开启事务
| |
事务的ACID特性
- 原子性(Atomicity)
最小的工作单元,整个工作单元要么一起提交成功,要么全部失败回滚
- 一致性(Consistency)
事务中操作的数据及状态改变是一致的,即写入资料的结果必须完全符合预设的规则,不会因为出现系统意外等原因导致状态的不一致
| |
- 隔离性(Isolation)
一个事务所操作的数据在提交之前,对其他事务的可见性设定(一般设定为不可见)
- 持久性(Durability)
事务所做的修改就会永久保存,不会因为系统意外导致数据的丢失
理解并发带来的脏读、幻读、不可重复读
- 脏读
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
- 不可重复读(同样的条件,你读取过的数据,再次读取出来发现值不一样了 )
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
- 幻读 ( 幻读的重点在于新增或者删除)
是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
事务的隔离级别
MySQL 8.0 查看事务的默认隔离级别
| |
- Read Uncommitted(未提交读简称RU) –未解决并发问题
事务未提交对其他事务也是可见的,也被称之为脏读(Dirty Read)。
- Read Committed(提交读简称RC) –解决脏读问题
事务成功提交后才可以被查询到,也被称为不可重复读(Nonrepeatable Read)。
- Repeatable Read (可重复读简称RR) –解决不可重复读问题
在同一个事务中多次读取同样的数据结果是一样的,这种隔离级别未定义解决幻读的问题MySQL默认级别;Innodb引擎通过MVCC来解决幻读问题
- Serializable(串行化) –解决所有问题
最高的隔离级别,通过强制事务的串行执行
Innodb对隔离级别的支持程度
Innodb事务的隔离级别是通过锁+MVCC实现的
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读(Read Uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read Committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable Read) | 不可能 | 不可能 | 对Innodb不可能(具体看MVCC) |
| 可串行化(Serializable) | 不可能 | 不可能 | 不可能 |
锁
锁是用于管理不同事务对共享资源的并发访问
表锁与行锁的区别:
锁定粒度:表锁 > 行锁
加锁效率:表锁 > 行锁
冲突概率:表锁 > 行锁
并发性能:表锁 < 行锁
InnoDB存储引擎支持行锁和表锁(整个表所有行加锁)
行锁
InnoDB的行锁是通过给索引上的索引项加锁来实现的。只有通过索引条件进行数据检索,InnoDB才使用行级锁,否则,InnoDB将使用表锁(锁住索引的所有记录)
| |
共享锁(Shared Locks)
| |
排他锁(Exclusive Locks)
| |
意向共享锁(IS)与意向排它锁(IX)
意向锁(IS、IX)是InnoDB数据操作之前自动加的,不需要用户干预,但是要理解有这么一个流程 意义:当事务想去进行锁表时,可以先判断意向锁是否存在,存在时则可快速返回该表不能启用表锁。
意向共享锁(IS)
表示事务准备给数据行加入共享锁,即一个数据行加共享锁前必须先取得该表的IS锁,意向共享锁之间是可以相互兼容的
意向排它锁(IX)
表示事务准备给数据行加入排他锁,即一个数据行加排他锁前必须先取得该表的IX锁,意向排它锁之间是可以相互兼容的
自增锁
针对自增列自增长的一个特殊的表级别锁; 开启事务,添加数据时,然后回滚了,那么这个id就永久消失了;
| |
记录锁(Record)间隙锁(Gap)临键锁(Next-key)
首先来看看测试的数据库表结构
Next-key locks临键锁(Innodb)
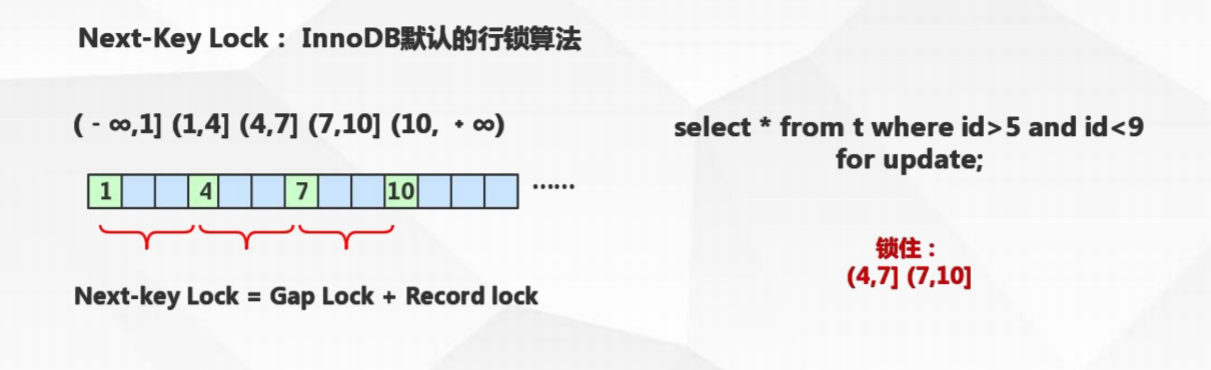 锁住记录+区间(左开右闭)
当sql执行按照索引进行数据的检索时,查询条件为范围查找(between and、<、>等)并有数据命中则此时SQL语句加上的锁为Next-key locks,锁住索引的记录+区间(左开右闭)
锁住记录+区间(左开右闭)
当sql执行按照索引进行数据的检索时,查询条件为范围查找(between and、<、>等)并有数据命中则此时SQL语句加上的锁为Next-key locks,锁住索引的记录+区间(左开右闭)
Gap locks间隙锁:
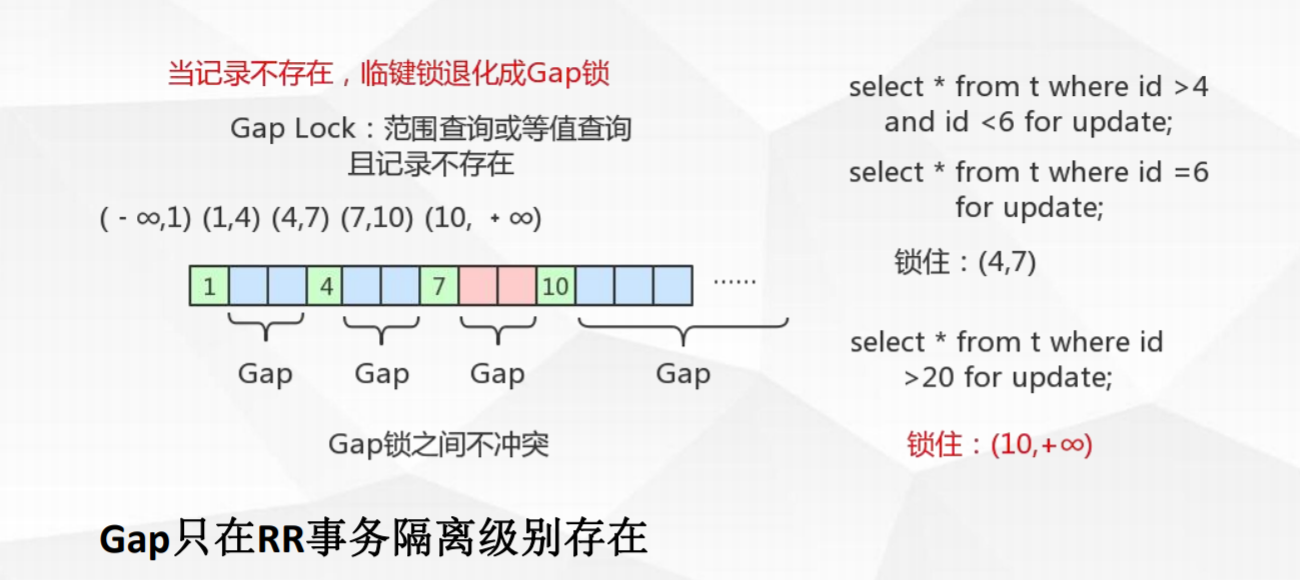 锁住数据不存在的区间(左开右开)
当sql执行按照索引进行数据的检索时,查询条件的数据不存在,这时SQL语句加上的锁即为Gap locks,锁住索引不存在的区间(左开右开)
锁住数据不存在的区间(左开右开)
当sql执行按照索引进行数据的检索时,查询条件的数据不存在,这时SQL语句加上的锁即为Gap locks,锁住索引不存在的区间(左开右开)
Record locks记录锁:
记录锁可以说是最好的性能了:只锁了一条记录:这就是我们为什么要键索引,索引要建立好的原因。
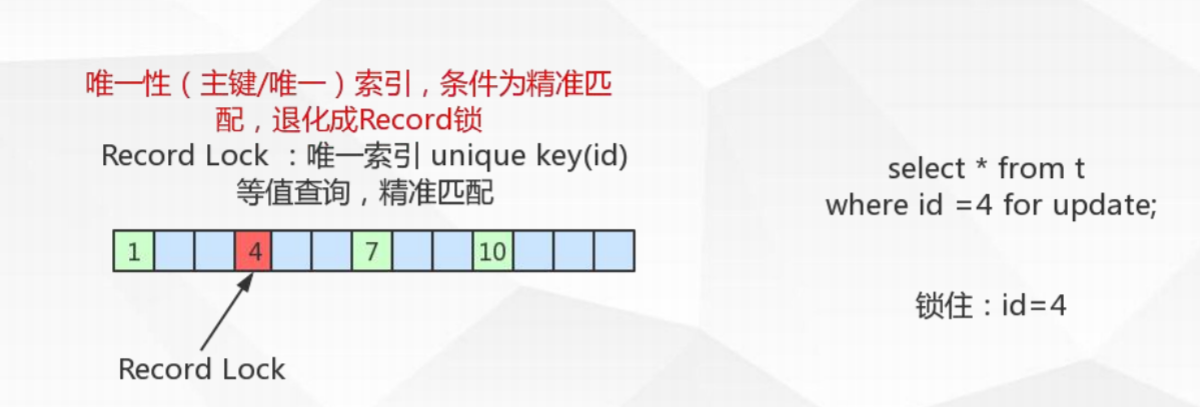 锁住具体的索引项
当sql执行按照唯一性(Primary key、Unique key)索引进行数据的检索时,查询条件等值匹配且查询的数据是存在,这时SQL语句加上的锁即为记录锁Record locks,锁住具体的索引项。
锁住具体的索引项
当sql执行按照唯一性(Primary key、Unique key)索引进行数据的检索时,查询条件等值匹配且查询的数据是存在,这时SQL语句加上的锁即为记录锁Record locks,锁住具体的索引项。
利用锁解决脏读、不可重复读、幻读
| |
死锁
多个并发事务(2个或者以上),事务之间产生加锁的循环等待,形成死锁。
怎样避免死锁
- 类似的业务逻辑以固定的顺序访问表和行。
- 大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概 率。
- 降低隔离级别,如果业务允许,将隔离级别调低也是较好的选择
- 为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁(或者说是表锁)
一但不走索引,innodb就会提升为表锁,这样就会增加死锁冲突几率