MySQL性能调优(1)理解底层B+tree机制
索引是谁实现的
索引是存储引擎实现的: 本文章主要对MySQL常用的MyISAM与InnoDB这两个存储引擎做分析。
索引是什么
索引是为了加速对表中的数据行的检索而创建的一种分散存储的数据结构。
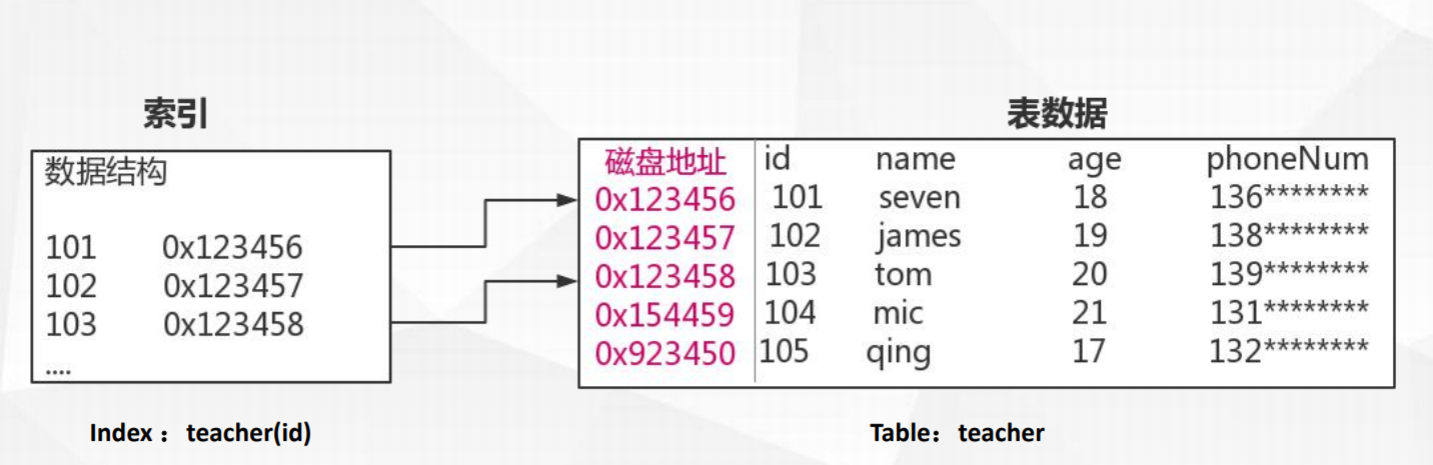
为什么要用索引
- 索引能极大的减少存储引擎需要扫描的数据量。(比如全表扫描就是在找数据)
- 索引可以把随机IO变成顺序IO。(因为索引是有序的这样就能保证找数据的时候稳定性,在程序中不允许有不稳定因素。)
为什么MySQL要用b+tree来实现索引
在这里先推荐一个网址来学习二叉树由来地址。
先来看看二叉查找树 Binary Search Tree

在来看看平衡二叉查找树(所有节点数高度不会超过1)AVL Trees (Balanced binary search trees)记住图上的磁盘块上存储了数据区的磁盘地址。
说说为什么MySQL没有选择这些算法而去选择B+Tree
- 它太深了,数据存在的(高)深度决定着他的IO操作次数,IO操作耗时大这个大家都是知道的。
- 他太小了,IO操作是很耗时,他一次IO也只能加载一个关键字;保存的东西太少了。
- 没有很好的利用操作磁盘IO的数据交换特性(操作系统通过硬盘读取数据一次IO操作读取的大小是4k(页为单位)) 这就是为什么SSD在分区时选择4k对其的原因,能使他大大提升读写性能。 二叉树每个节点只有一个关键字,他是存满不了4k的,这样会浪费资源。
- 也没有利用好磁盘IO的预读能力(空间局部性原理),从而带来频繁的IO操作。空间局部性原理就是: 操作系统每次IO操作读取一页,他会有预读能力,把下一页或者后面几页的数据读取。(注:MySQL定义的一页为16k)


