SynchronousQueue 是实现了BlockingQueue的一个队列。特点是SynchronousQueue 没有容器。
在生产者消费者情况下。生产者生产数据后没人消费是会阻塞的。当有消费者消费了,消费者与生产者同时退出队列。
SynchronousQueue 的两种实现方式
- 公平模式 就是队列 TransferQueue
- 非公平模式 就是栈 TransferStack
Transferer 抽象类
不管非公平还是公平都是这个抽象方法来实现的数据交换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| abstract static class Transferer<E> {
/**
* @param e 可以为null,null时表示这个请求是一个 REQUEST 类型的请求
* 如果不是null,说明这个请求是一个 DATA 类型的请求。
*
* @param timed
* 如果为true 表示指定了超时时间 ,如果为false 表示不支持超时,表示当前请求一直等待到匹配为止,或者被中断。
* @param nanos 超时时间限制 单位 纳秒
*
* @return E
* 如果当前请求是一个 REQUEST类型的请求,返回值如果不为null 表示 匹配成功,
* 如果返回null,表示REQUEST类型的请求超时 或 被中断。
* 如果当前请求是一个 DATA 类型的请求,返回值如果不为null 表示 匹配成功,返回当前线程put的数据。
* 如果返回值为null 表示,DATA类型的请求超时 或者 被中断..都会返回Null。
*/
abstract E transfer(E e, boolean timed, long nanos);
}
|
put|take
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
|
非公平模式的实现分析
其实主要还是节点进来 就判断与栈顶是否相同
相同 入栈 并把自己改成栈顶
不同 就尝试匹配
这里面有一个fulfilling状态是正在匹配的节点

TransferStack基本字段说明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| /** 表示Node类型为 消费者请求类型 */
static final int REQUEST = 0;
/** 表示Node类型为 生产者数据类型 */
static final int DATA = 1;
/** 表示Node类型为 匹配中类型
* 假设栈顶元素为 REQUEST-NODE,当前请求类型为 DATA的话,入栈会修改类型为 FULFILLING 【栈顶 & 栈顶之下的一个node】。
* 假设栈顶元素为 DATA-NODE,当前请求类型为 REQUEST的话,入栈会修改类型为 FULFILLING 【栈顶 & 栈顶之下的一个node】。
*/
static final int FULFILLING = 2;
static final class SNode {
//指向下一个栈帧
volatile SNode next;
//与当前node匹配的节点
volatile SNode match;
//假设当前node对应的线程 自旋期间未被匹配成功,那么node对应的线程需要挂起,挂起前 waiter 保存对应的线程引用,
//方便 匹配成功后,被唤醒。
volatile Thread waiter;
//数据域,data不为空 表示当前Node对应的请求类型为 DATA类型。 反之则表示Node为 REQUEST类型。
Object item;
//表示当前Node的模式 【DATA/REQUEST/FULFILLING】
int mode;
|
transfer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
| E transfer(E e, boolean timed, long nanos) {
//包装当前线程的Node
SNode s = null; // constructed/reused as needed
//e == null 条件成立:当前线程是一个REQUEST线程。
//否则 e!=null 说明 当前线程是一个DATA线程,提交数据的线程。
int mode = (e == null) ? REQUEST : DATA;
//自旋
for (;;) {
//h 表示栈顶指针
SNode h = head;
//CASE1:当前栈内为空 或者 栈顶Node模式与当前请求模式一致,都是需要做入栈操作。
if (h == null || h.mode == mode) { // empty or same-mode
//条件一:成立,说明当前请求是指定了 超时限制的
//条件二:nanos <= 0 , nanos == 0. 表示这个请求 不支持 “阻塞等待”。
if (timed && nanos <= 0) { // can't wait
//条件成立:说明栈顶已经取消状态了,协助栈顶出栈。
// 里面判断就是判断当前线程是否等于node 的match 取消的时候会这样赋值
if (h != null && h.isCancelled())
// 重新设置栈顶为下一个
casHead(h, h.next); // pop cancelled node
else
//大部分生产者情况从这里返回。
return null;
}
//什么时候执行else if 呢?queue.offer();也可能是put 过来的
//当前栈顶为空 或者 模式与当前请求一致,且当前请求允许 阻塞等待。
//casHead(h, s = snode(s, e, h, mode)) 入栈操作。 把当前node设置为头部
else if (casHead(h, s = snode(s, e, h, mode))) {
// 主要还是下面逻辑会阻塞线程
//执行到这里,说明 当前请求入栈成功。
// 等待被匹配!
//1.正常情况:返回匹配的节点 里面阻塞与自旋的时候会匹配节点 如果匹配成功或者其他线程唤醒了他 都会返回数据
//2.取消情况:返回当前节点 s节点进去,返回s节点...
SNode m = awaitFulfill(s, timed, nanos);
//条件成立:说明当前Node状态是 取消状态...
if (m == s) { // wait was cancelled
//将取消状态的节点 出栈...
clean(s);
//取消状态 最终返回null
return null;
}
//执行到这里 被唤醒 说明当前Node已经被匹配了...
//条件一:成立,说明栈顶是有Node
//条件二:成立,说明 Fulfill 和 当前Node 还未出栈,需要协助出栈。
if ((h = head) != null && h.next == s)
//将fulfill 和 当前Node 结对 出栈
casHead(h, s.next); // help s's fulfiller
//当前NODE模式为REQUEST类型:返回匹配节点的m.item 数据域
//当前NODE模式为DATA类型:返回Node.item 数据域,当前请求提交的 数据e
return (E) ((mode == REQUEST) ? m.item : s.item);
}
}
//栈顶Node的模式与当前请求的模式不一致,会执行else if 的条件。
//栈顶是 (DATA Reqeust) (Request DATA) (FULFILLING REQUEST/DATA)
//CASE2:当前栈顶模式与请求模式不一致,且栈顶不是FULFILLING
else if (!isFulfilling(h.mode)) { // try to fulfill
//条件成立:说明当前栈顶状态为 取消状态,当前线程协助它出栈。
if (h.isCancelled()) // already cancelled
//协助 取消状态节点 出栈。
casHead(h, h.next); // pop and retry
//条件成立:说明压栈节点成功,入栈一个 FULFILLING | mode 按位与
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
//当前请求入栈成功 现在头结点和头结点下一个 开始匹配了
//自旋,fulfill 节点 和 fulfill.next 节点进行匹配工作...
for (;;) { // loop until matched or waiters disappear
//m 与当前s 匹配节点。
SNode m = s.next; // m is s's match
//m == null 什么时候可能成立呢? !!!!
//当s.next节点 超时或者被外部线程中断唤醒后,会执行 clean 操作 将 自己清理出栈,此时
//站在匹配者线程 来看,真有可能拿到一个null。
if (m == null) { // all waiters are gone
//将整个栈清空。
casHead(s, null); // pop fulfill node
s = null; // use new node next time
//回到外层大的 自旋中,再重新选择路径执行,此时有可能 插入一个节点。
break; // restart main loop
}
//什么时候会执行到这里呢?
//fulfilling 匹配节点不为null,进行真正的匹配工作。
//获取 匹配节点的 下一个节点。
SNode mn = m.next;
//尝试匹配,匹配成功,则将fulfilling 和 m 一起出栈。
if (m.tryMatch(s)) {
//结对出栈
casHead(s, mn); // pop both s and m
//当前NODE模式为REQUEST类型:返回匹配节点的m.item 数据域
//当前NODE模式为DATA类型:返回Node.item 数据域,当前请求提交的 数据e
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
//强制出栈 cas 失败只有可能有线程超时了 这样就让超时的线程出栈就行了
s.casNext(m, mn); // help unlink
}
}
}
//CASE3:什么时候会执行?
//栈顶模式为 FULFILLING模式,表示栈顶和栈顶下面的栈帧正在发生匹配...
//当前请求需要做 协助 工作。
else { // help a fulfiller
//h 表示的是 fulfilling节点,m fulfilling匹配的节点。
SNode m = h.next; // m is h's match
//m == null 什么时候可能成立呢?
//当s.next节点 超时或者被外部线程中断唤醒后,会执行 clean 操作 将 自己清理出栈,此时
//站在匹配者线程 来看,真有可能拿到一个null。
if (m == null) // waiter is gone
//清空栈
casHead(h, null); // pop fulfilling node
//大部分情况:走else分支。
else {
//获取栈顶匹配节点的 下一个节点
SNode mn = m.next;
//条件成立:说明 m 和 栈顶 匹配成功
if (m.tryMatch(h)) // help match
//双双出栈,让栈顶指针指向 匹配节点的下一个节点。
casHead(h, mn); // pop both h and m
else // lost match
//强制出栈
h.casNext(m, mn); // help unlink
}
}
}
}
|
tryMatch 尝试匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| /*
* 尝试匹配
* 调用tryMatch的对象是 栈顶节点的下一个节点,与栈顶匹配的节点。
*
* @return ture 匹配成功。 否则匹配失败..
*/
boolean tryMatch(SNode s) {
//条件一:match == null 成立,说明当前Node尚未与任何节点发生过匹配...
//条件二 成立:使用CAS方式 设置match字段,表示当前Node已经被匹配了
if (match == null &&
UNSAFE.compareAndSwapObject(this, matchOffset, null, s)) {
//当前Node如果自旋结束,那么会使用LockSupport.park 方法挂起,挂起之前会将Node对应的Thread 保留到 waiter字段。
Thread w = waiter;
//条件成立:说明Node对应的Thread已经挂起了...
if (w != null) { // waiters need at most one unpark
waiter = null;
//使用unpark方式唤醒。
LockSupport.unpark(w);
}
return true;
}
return match == s;
}
|
awaitFulfill 阻塞&自旋等待
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| SNode awaitFulfill(SNode s, boolean timed, long nanos) {
//等待的截止时间。 timed == true => System.nanoTime() + nanos
final long deadline = timed ? System.nanoTime() + nanos : 0L;
//获取当前请求线程..
Thread w = Thread.currentThread();
//spins 表示当前请求线程 在 下面的 for(;;) 自旋检查中,自旋次数。
// 如果达到spins自旋次数时,当前线程对应的Node 仍然未被匹配成功,
//那么再选择 挂起 当前请求线程。
int spins = (shouldSpin(s) ?
//timed == true 指定了超时限制的,这个时候采用 maxTimedSpins == 32 ,否则采用 32 * 16
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
//自旋检查逻辑:1.是否匹配 2.是否超时 3.是否被中断..
for (;;) {
//条件成立:说明当前线程收到中断信号,需要设置Node状态为 取消状态。
if (w.isInterrupted())
//Node对象的 match 指向 当前Node 说明该Node状态就是 取消状态。
// 这里取消指向了自己
s.tryCancel();
//m 表示与当前Node匹配的节点。
//1.正常情况:有一个请求 与 当前Node 匹配成功,这个时候 s.match 指向 匹配节点。
//2.取消情况:当前match 指向 当前Node...
SNode m = s.match;
if (m != null)
//可能正常 也可能是 取消... 外面有判断
return m;
//条件成立:说明指定了超时限制..
if (timed) {
//nanos 表示距离超时 还有多少纳秒..
nanos = deadline - System.nanoTime();
//条件成立:说明已经超时了...
if (nanos <= 0L) {
//设置当前Node状态为 取消状态.. match-->当前Node
s.tryCancel();
continue;
}
}
//条件成立:说明当前线程还可以进行自旋检查...
if (spins > 0)
//自旋次数 累积 递减。。。
spins = shouldSpin(s) ? (spins-1) : 0;
//spins == 0 ,已经不允许再进行自旋检查了
else if (s.waiter == null)
// node 存储当前线程的引用
//把当前Node对应的Thread 保存到 Node.waiter字段中..
s.waiter = w; // establish waiter so can park next iter
//条件成立:说明当前Node对应的请求 未指定超时限制。
else if (!timed)
// 一般是这里阻塞
//使用不指定超时限制的park方法 挂起当前线程,直到 当前线程被外部线程 使用unpark唤醒。
LockSupport.park(this);
//什么时候执行到这里? timed == true 设置了 超时限制..
//条件成立:nanos > 1000 纳秒的值,只有这种情况下,才允许挂起当前线程..否则 说明 超时给的太少了...挂起和唤醒的成本 远大于 空转自旋...
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
boolean shouldSpin(SNode s) {
//获取栈顶
SNode h = head;
//条件一 h == s :条件成立 说明当前s 就是栈顶,允许自旋检查...
//条件二 h == null : 什么时候成立? 当前s节点 自旋检查期间,又来了一个 与当前s 节点匹配的请求,双双出栈了...条件会成立。
//条件三 isFulfilling(h.mode):前提 当前 s 不是 栈顶元素。并且当前栈顶正在匹配中,这种状态 栈顶下面的元素,都允许自旋检查。
return (h == s || h == null || isFulfilling(h.mode));
}
|
clean 清空线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| void clean(SNode s) {
//清空数据域
s.item = null; // forget item
//释放线程引用..
s.waiter = null; // forget thread
//检查取消节点的截止位置
SNode past = s.next;
if (past != null && past.isCancelled())
past = past.next;
// Absorb cancelled nodes at head
//当前循环检查节点
SNode p;
//从栈顶开始向下检查,将栈顶开始向下连续的 取消状态的节点 全部清理出去,直到碰到past为止。
while ((p = head) != null && p != past && p.isCancelled())
casHead(p, p.next);
// Unsplice embedded nodes
while (p != null && p != past) {
//获取p.next
SNode n = p.next;
// 跳过出栈的node 设置p.next
if (n != null && n.isCancelled())
p.casNext(n, n.next);
else
p = n;
}
}
|
公平模式的实现分析
主要是 节点进来判断链表尾结点是否与自己相同
相同 我就进入链表并把自己设置为尾结点
不同 就与链表头结点互补出队
TransferQueue基本字段说明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| static final class QNode {
//指向当前节点的下一个节点,组装链表使用的。
volatile QNode next;
//数据域 Node代表的是DATA类型,item表示数据 否则 Node代表的REQUEST类型,item == null
volatile Object item;
//当Node对应的线程 未匹配到节点时,对应的线程 最终会挂起,挂起之前会保留 线程引用到waiter ,
//方法 其它Node匹配当前节点时 唤醒 当前线程..
volatile Thread waiter;
//true 当前Node是一个DATA类型 false表示当前Node是一个REQUEST类型。
final boolean isData;
QNode(Object item, boolean isData) {
this.item = item;
this.isData = isData;
}
//修改当前节点next引用
boolean casNext(QNode cmp, QNode val) {
return next == cmp &&
UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
//修改当前节点数据域item
boolean casItem(Object cmp, Object val) {
return item == cmp &&
UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
|
transfer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
| E transfer(E e, boolean timed, long nanos) {
//s 指向当前请求 对应Node
QNode s = null; // constructed/reused as needed
//isData == true 表示 当前请求是一个写数据操作(DATA) 否则isData == false 表示当前请求是一个 REQUEST操作。
boolean isData = (e != null);
//自旋..
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null)
continue;
//CASE1:入队
//条件一:成立,说明head和tail同时指向dummy节点,当前队列实际情况 就是 空队列。
// 此时当前请求需要做入队操作,因为没有任何节点 可以去匹配。
//条件二:队列不是空,队尾节点与当前请求类型是一致的情况。说明也是无法完成匹配操作的情况,此时当前节点只能入队...
if (h == t || t.isData == isData) {
//获取当前队尾t 的next节点 tn - t.next
QNode tn = t.next;
//因为多线程环境,当前线程在入队之前,其它线程有可能已经入队过了..改变了 tail 引用。
if (t != tail)
//线程回到自旋...再选择路径执行。
continue ;
//条件成立:说明已经有线程 入队了,且只完成了 入队的 第一步:设置t.next = newNode, 第二步可能尚未完成..
if (tn != null) {
//协助更新tail 指向新的 尾结点。
advanceTail(t, tn);
//线程回到自旋...再选择路径执行。
continue;
}
//条件成立:说明当前调用transfer方法的 上层方法 可能是 offer() 无参的这种方法进来的,这种方法不支持 阻塞等待...
if (timed && nanos <= 0)
//检查未匹配到,直接返回null。
return null;
//条件成立:说明当前请求尚未 创建对应的node
if (s == null)
//创建node过程...
s = new QNode(e, isData);
//条件 不成立:!t.casNext(null, s) 说明当前t仍然是tail,当前线程对应的Node入队的第一步 完成!
if (!t.casNext(null, s))
//更新队尾 为咱们请求节点。
advanceTail(t, s);
//当前节点 等待匹配....
//当前请求为DATA模式时:e 请求带来的数据
//x == this 当前SNode对应的线程 取消状态
//x == null 表示已经有匹配节点了,并且匹配节点拿走了item数据。
//当前请求为REQUEST模式时:e == null
//x == this 当前SNode对应的线程 取消状态
//x != null 且 item != this 表示当前REQUEST类型的Node已经匹配到一个DATA类型的Node了。
Object x = awaitFulfill(s, e, timed, nanos);
//说明当前Node状态为 取消状态,需要做 出队逻辑。
if (x == s) { // wait was cancelled
//清理出队逻辑,最后讲。
clean(t, s);
return null;
}
//执行到这里说明 当前Node 匹配成功了...
//1.当前线程在awaitFulfill方法内,已经挂起了...此时运行到这里时是被 匹配节点的线程使用LockSupport.unpark() 唤醒的..
//被唤醒:当前请求对应的节点,肯定已经出队了,因为匹配者线程 是先让当前Node出队的,再唤醒当前Node对应线程的。
// 这个条件会打开下面的是否在队列条件
//2.当前线程在awaitFulfill方法内,处于自旋状态...此时匹配节点 匹配后,它检查发现了,然后返回到上层transfer方法的。
//自旋状态返回时:当前请求对应的节点,不一定就出队了...
//被唤醒时:s.isOffList() 条件会成立。 !s.isOffList() 不会成立。
//条件成立:说明当前Node仍然在队列内,需要做 匹配成功后 出队逻辑。
if (!s.isOffList()) {
//其实这里面做的事情,就是防止当前Node是自旋检查状态时发现 被匹配了,然后当前线程 需要将
//当前线程对应的Node做出队逻辑.
//t 当前s节点的前驱节点,更新dummy节点为 s节点。表示head.next节点已经出队了...
advanceHead(t, s);
//x != null 且 item != this 表示当前REQUEST类型的Node已经匹配到一个DATA类型的Node了。
//因为s节点已经出队了,所以需要把它的item域 给设置为它自己,表示它是个取消出队状态。
if (x != null)
s.item = s;
//因为s已经出队,所以waiter一定要保证是null。
s.waiter = null;
}
//x != null 成立,说明当前请求是REQUEST类型,返回匹配到的数据x
//x != null 不成立,说明当前请求是DATA类型,返回DATA请求时的e。
return (x != null) ? (E)x : e;
}
//CASE2:队尾节点 与 当前请求节点 互补 (队尾->DATA,请求类型->REQUEST) (队尾->REQUEST, 请求类型->DATA)
else {
//h.next节点 其实是真正的队头,请求节点 与队尾模式不同,需要与队头 发生匹配。因为TransferQueue是一个 公平模式
QNode m = h.next;
//条件一:t != tail 什么时候成立呢? 肯定是并发导致的,其它线程已经修改过tail了,
//有其它线程入队过了..当前线程看到的是过期数据,需要重新循环
//条件二:m == null 什么时候成立呢? 肯定是其它请求先当前请求一步,匹配走了head.next节点。
//条件三:条件成立,说明已经有其它请求匹配走head.next了。。。当前线程看到的是过期数据。。。重新循环...
if (t != tail || m == null || h != head)
continue;
//执行到这里,说明t m h 不是过期数据,是准确数据。目前来看是准确的!
//获取匹配节点的数据域 保存到x
Object x = m.item;
//条件一:在data类型数据为空 在req类型数据域不为空这种特殊情况
//条件二:条件成立,说明m节点已经是 取消状态了...不能完成匹配,当前请求需要continue,
//条件三:!m.casItem(x, e),前提条件 m 非取消状态。
//1.假设当前请求为REQUEST类型 e == null
//m 是 DATA类型了...
//相当于将匹配的DATA Node的数据域清空了,相当于REQUEST 拿走了 它的数据。
//2.假设当前请求为DATA类型 e != null
//m 是 REQUEST类型了...
//相当于将匹配的REQUEST Node的数据域 填充了,填充了 当前DATA 的 数据。相当于传递给REQUEST请求数据了...
if (isData == (x != null) ||
x == m ||
!m.casItem(x, e)) {
advanceHead(h, m);
continue;
}
//执行到这里,说明匹配已经完成了,匹配完成后,需要做什么?
//1.将真正的头节点 出队。让这个真正的头结点成为dummy节点
advanceHead(h, m);
//2.唤醒匹配节点的线程..
LockSupport.unpark(m.waiter);
//x != null 成立,说明当前请求是REQUEST类型,返回匹配到的数据x
//x != null 不成立,说明当前请求是DATA类型,返回DATA请求时的e。
return (x != null) ? (E)x : e;
}
}
}
|
出队操作
1
2
3
4
5
6
7
8
9
10
| /**
* Tries to cas nh as new head; if successful, unlink
* old head's next node to avoid garbage retention.
* 设置头指针指向新的节点,蕴含操作:老的头节点出队。
*/
void advanceHead(QNode h, QNode nh) {
if (h == head &&
UNSAFE.compareAndSwapObject(this, headOffset, h, nh))
h.next = h; // forget old next
}
|
awaitFulfill 阻塞&自旋等待
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
//deadline 表示等待截止时间...
final long deadline = timed ? System.nanoTime() + nanos : 0L;
//当前请求节点的线程..
Thread w = Thread.currentThread();
//允许自旋检查的次数..
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
//自旋:1.检查状态等待匹配 2.挂起线程 3.检查状态 是否被中断 或者 超时..
for (;;) {
//条件成立:说明线程等待过程中,收到了中断信号,属于中断唤醒..
if (w.isInterrupted())
//更新线程对应的Node状态为 取消状态..
//数据域item 指向当前Node自身,表示取消状态.
s.tryCancel(e);
//获取当前Node数据域
Object x = s.item;
//item有几种情况呢?
//当SNode模式为DATA模式时:
//1.item != null 且 item != this 表示请求要传递的数据 put(E e)
//2.item == this 当前SNode对应的线程 取消状态
//3.item == null 表示已经有匹配节点了,并且匹配节点拿走了item数据。
//当SNode模式为REQUEST模式时:
//1.item == null 时,正常状态,当前请求仍然未匹配到对应的DATA请求。
//2.item == this 当前SNode对应的线程 取消状态
//3.item != null 且 item != this 表示当前REQUEST类型的Node已经匹配到一个DATA类型的Node了。
//条件成立:
//当前请求为DATA模式时:e 请求带来的数据
//item == this 当前SNode对应的线程 取消状态
//item == null 表示已经有匹配节点了,并且匹配节点拿走了item数据。
//当前请求为REQUEST模式时:e == null
//item == this 当前SNode对应的线程 取消状态
//item != null 且 item != this 表示当前REQUEST类型的Node已经匹配到一个DATA类型的Node了。
if (x != e)
return x;
//条件成立:说明请求指定了超时限制..
if (timed) {
//nanos表示距离截止时间的长度..
nanos = deadline - System.nanoTime();
//条件成立:说明当前Node对应的线程 已经等待超时了,需要取消了.
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
//条件成立:说明当前线程 还可以进行自旋检查..
if (spins > 0)
//递减..
--spins;
//执行到这里,说明spins == 0;
//条件成立:当前Node尚未设置waiter字段..
else if (s.waiter == null)
//保存当前Node对应的线程,方便后面挂起线程后,外部线程使用s.waiter字段唤醒 当前Node对应的线程。
s.waiter = w;
//条件成立:说明当前请求未指定超时限制。挂起采用 不指定超时的挂起方法..
else if (!timed)
LockSupport.park(this);
//执行到这里,说明 timed==true
//条件 不成立:nanos 太小了,没有必要挂起线程了,还不如自旋 实在。
else if (nanos > spinForTimeoutThreshold)
//nanos > 1000.
LockSupport.parkNanos(this, nanos);
}
}
|
清空
示例代码-队首节点取消逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| public static void main(String[] args) throws InterruptedException {
SynchronousQueue<Integer> queue = new SynchronousQueue<>(true);
Thread thread1 = new Thread(() -> {
try {
queue.put(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread1.start();
Thread.sleep(1000);
Thread thread2 = new Thread(() -> {
try {
queue.put(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread2.start();
Thread.sleep(100);
thread1.interrupt();
}
|
流程图
.png!print)
.png!print)
.png!print)
示例代码-队中节点取消逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public static void main(String[] args) throws InterruptedException {
SynchronousQueue<Integer> queue = new SynchronousQueue<>(true);
Thread thread1 = new Thread(() -> {
try {
queue.put(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread1.start();
Thread.sleep(200);
Thread thread2 = new Thread(() -> {
try {
queue.put(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread2.start();
Thread.sleep(200);
Thread thread3 = new Thread(() -> {
try {
queue.put(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread3.start();
Thread.sleep(200);
thread2.interrupt();
}
|
流程图
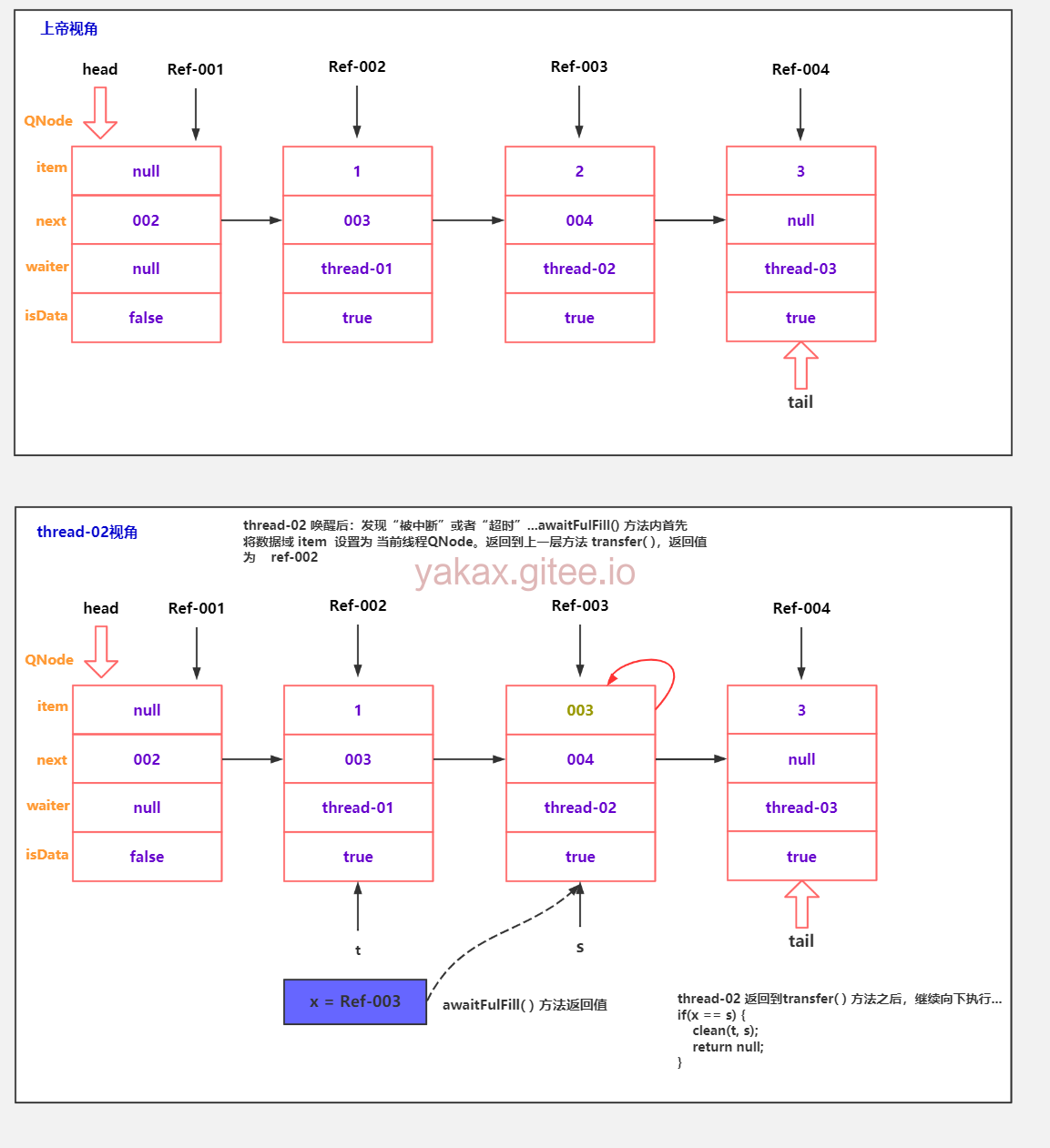
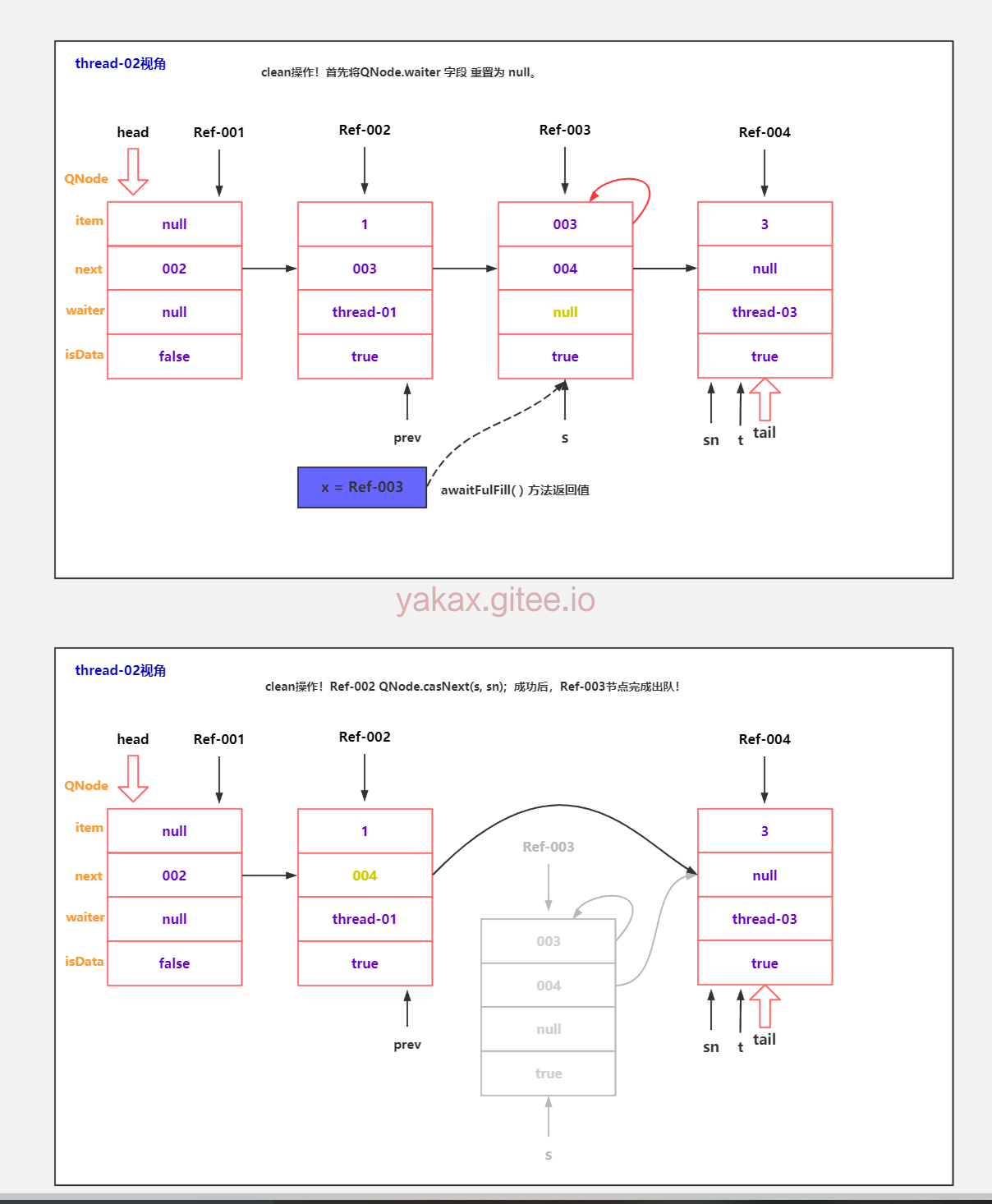
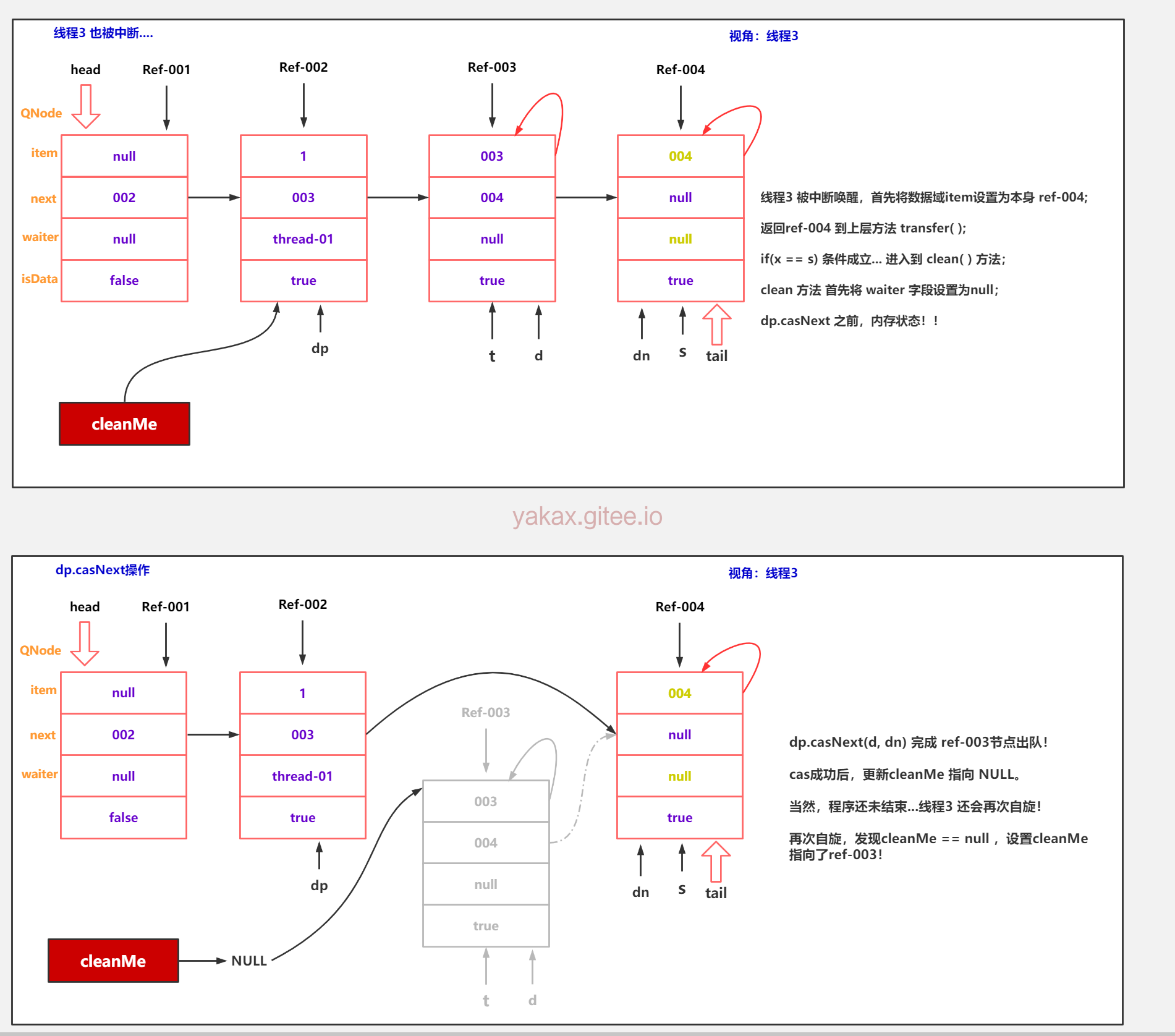
示例代码-队尾节点取消逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| public static void main(String[] args) throws InterruptedException {
SynchronousQueue<Integer> queue = new SynchronousQueue<>(true);
Thread thread1 = new Thread(() -> {
try {
queue.put(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread1.start();
Thread.sleep(200);
Thread thread2 = new Thread(() -> {
try {
queue.put(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread2.start();
Thread.sleep(200);
thread2.interrupt();
Thread.sleep(200);
Thread thread3 = new Thread(() -> {
try {
queue.put(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread3.start();
Thread.sleep(200);
thread3.interrupt();
}
|
流程图
.png!print)